読み取りの長さと品質を高エラーの読み取りデータと一緒に常に考慮することが重要であり、現在の長読み取りテクノロジー(MinIONやPacBioなど)ではエラー率が高くなっています。 読み取りの長さと品質を一緒に検討すると、実行がどれだけ成功したか、「高品質」であった読み取りの数、長い読み取りが「本物」(または単にポアノイズ)であるかどうかなどを判断するのに役立ちます。
最近、同様の区画に関心が急上昇し、 pauvre(フランス語で「貧しい」、「毛穴で遊ぶ」)というプロジェクトに出くわしました。 ')Oxford Nanopore Technologies(ONT)コミュニティを通じて、MinKNOWの基本的な呼び出しプロットよりも優れていると思います。さらに、MinKNOWとは異なり、いつでも必要なときにfastqファイルからこれらのプロットを生成できます。
[注:私は元の作成者ではありませんが、気に入った(そして必要だった)ため、現在貢献しています。]
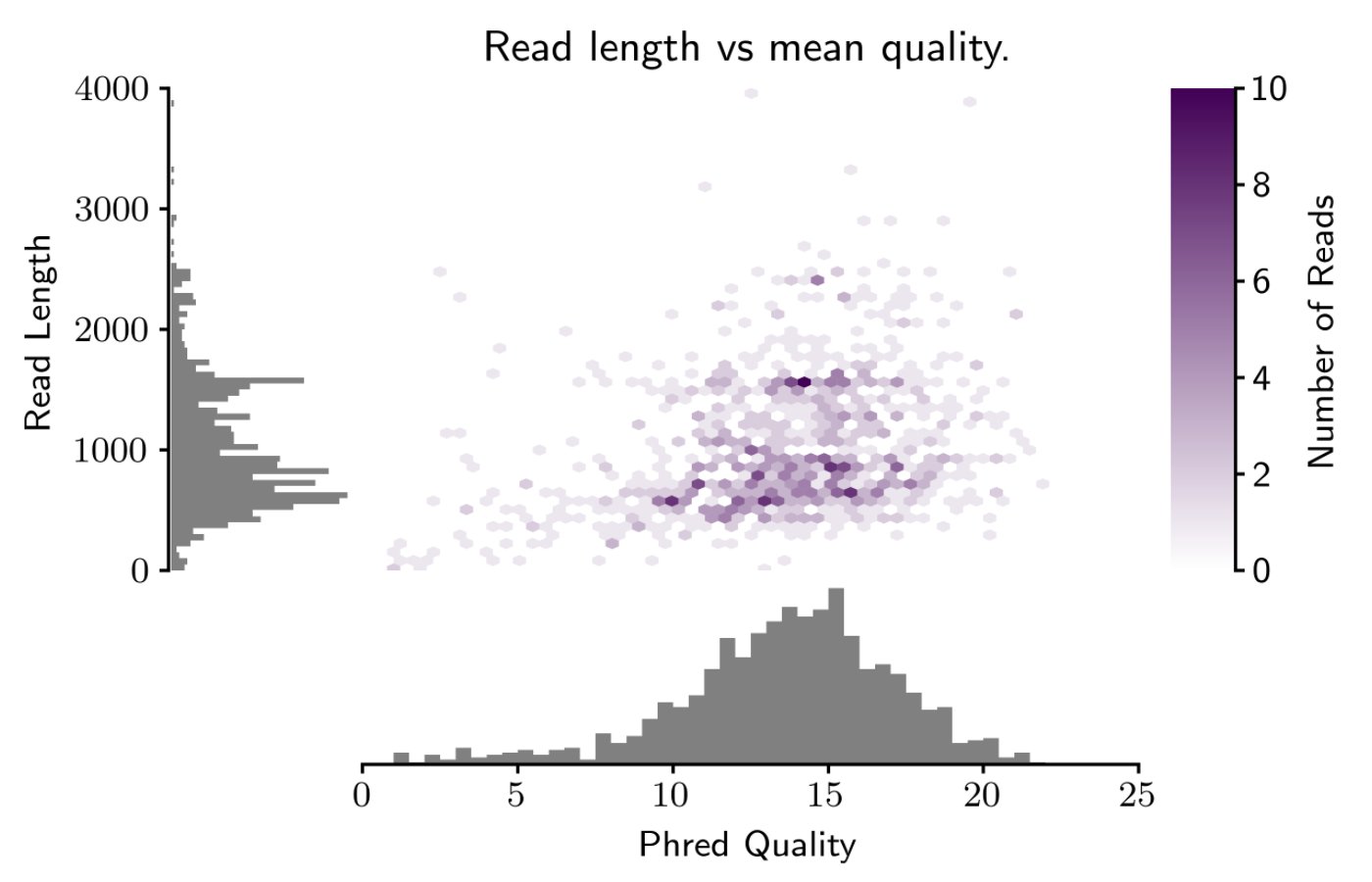
Pauvreは有用な統計も報告します:
fastq_runid_bb8b8ddedb22bdd6802b2bfa2b4e424c92c30d28_0.fastqnumReads:2164829numBasepairs:4970615217mean :1495.0minLen:5maxLen:392031N50:3450L50:402786塩基対> =平均PHREDおよび長さによるビンminLenQ0 Q5 Q10 Q15 Q17.5 Q20 Q21.5 Q25 Q25.5 Q30 0 4970615217 4970611559 4835461771 3889995868 2900103275 1087779109 1656 270324 160128 50729 50729 0 0 0 0100000 6260554 6260554 0 0 0 0 0 0 0 0150000 3504240 3504240 0 0 0 0 0 0 0 0200000 2501101 2501101 0 0 0 0 0 0 0 0
250000 1609592 1609592 0 0 0 0 0 0 0 0300000 1033423 1033423 0 0 0 0 0 0 0 0350000 392031 392031 0 0 0 0 0 0 00読み取り数> =平均値によるビンPhred + LenminLen Q0 Q5 Q10 Q15 Q17.5 Q20 Q21.5 Q25 Q25.5 Q30 0 2164829 2164605 2083436 1626706 1183812 435687 77341 1 0 0 50000 109109 5 3 1 1 0 0 0 0100000 36 36 0 0 0 0 0 0 0 0150000 15 15 0 0 0 0 0 0 0 0200000 9 9 0 0 0 0 0 0 0 0250000 5 5 0 0 0 0 0 0 0 0300000 3 3 0 0 0 0 0 0 0 0350000 1 1 0 0 0 0 0 0 0 0
これらのプロットと統計はPacBioでも同様に役立ちますが、それはスーパーではありませんSequelシーケンサーからの現在の生の出力で簡単に(可能ですが): PacBioはどの品質スコアエンコーディングを使用しますか?
Pauvreは現在Biopythonを使用していますfastqと matplotlib を解析して実際のプロットを作成し、出力画像形式(.png、.pdfなど)を選択できるようにします。背景を透明にするか白にするかを選択することもできます(.png出力の場合)。
パーサーは SeqIO.parse を使用しているため、現在非常に低速ですが、パーサーを変更して高速化しています。また、いくつかの追加機能を追加しています(たとえば、マージンヒストグラムにy軸を含めるかどうかを選択したり、ドキュメント用にいくつかの統計をプロットに直接印刷したりするなど)
現在、紫は(私が個人的に気に入っている)唯一の色の選択肢ですが、変更するオプションを追加するのは非常に簡単です。